
Last year, the Checkmarx Security Research Team decided to investigate Kubernetes due to the growing usage of it worldwide. For those who are not too familiar with this technology, you can find more information at the official site here. Kubernetes is an open-source framework written in the Go language, originally designed and developed by Google to automate deployment, scaling, and management of containerized applications.
To understand what we discovered, it’s important to know some of the Kubernetes basics. Kubernetes’ purpose is to orchestrate a cluster of servers, named nodes, and each node is able to host Pods. Pods are processes, running on a node, that encapsulate an application. Keep in mind that an application can consist on a single or multiple containers. This allows Kubernetes to automatically increase resources as the applications require, by creating/deleting more Pods of the same application.
There will be a Master node and Worker nodes on a cluster. The Master node runs the kube-apiserver process that allows the Master to monitor and control the Workers. On the Workers side, the communication with the Master is done by the kubelet process, and the kube-proxy process reflects the networking services of the Pods, allowing users to interact with the applications. The following diagram illustrates the main components of Kubernetes and how they interact.
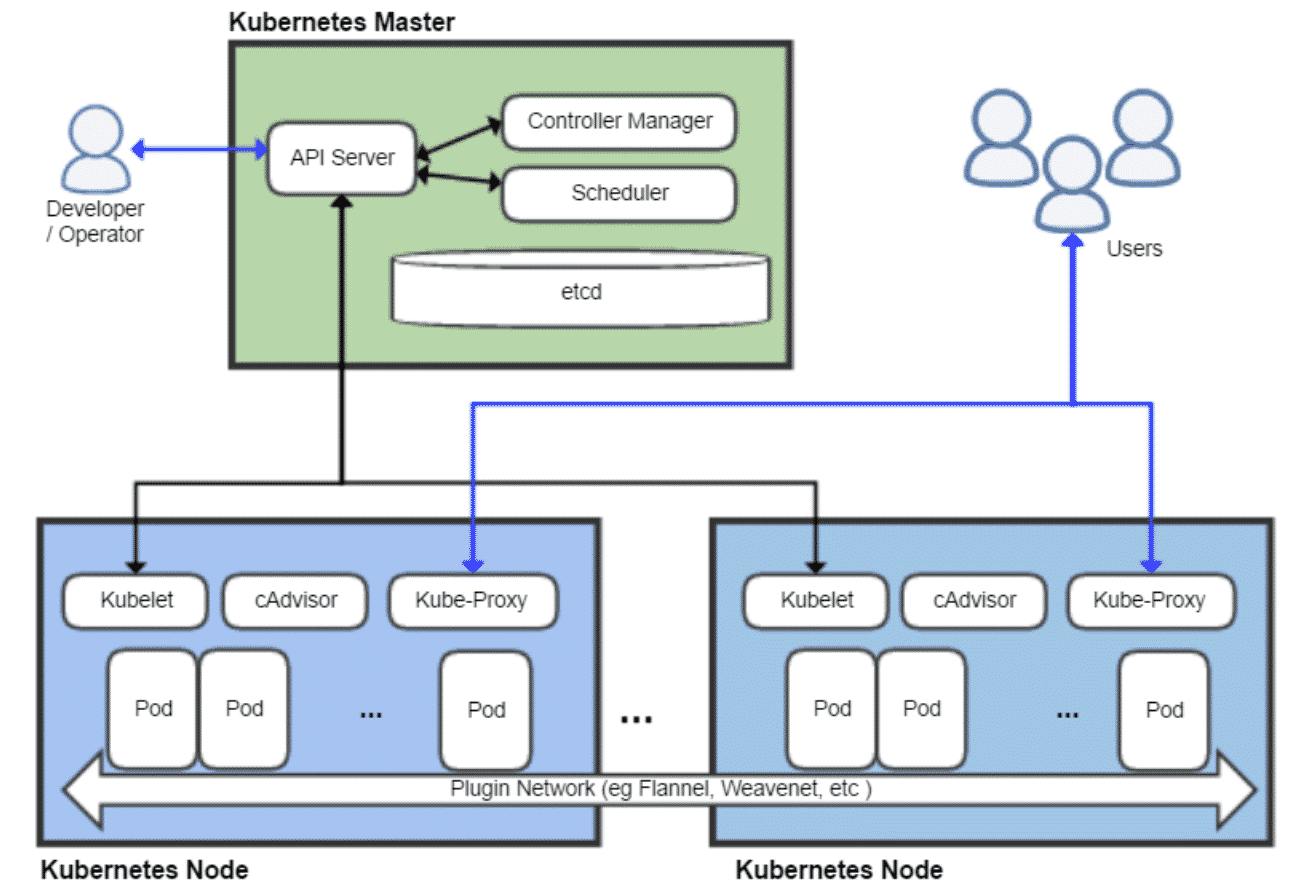
(source: https://en.wikipedia.org/wiki/Kubernetes)
To look for vulnerabilities in Kubernetes, we needed a lab environment with multiple servers. For this, it was decided to use virtual machines rather than physical ones, because they are much faster to configure every time there is the need to re-create the lab. To automate the lab creation and re-creation process, we used Terraform, Packer and Ansible. The vulnerability that we discovered in Kubernetes was uncovered by this automation process.
While creating the lab, we reused the Packer image without changing the hostname of the servers by mistake, and when we promoted the servers to Kubernetes cluster members, we realized that the cluster was unstable. The CPU load on the Master node was very high and eventually the cluster crashed!
We couldn’t understand what was causing this behavior. Although we had mistakenly configured servers in the cluster with the same hostname, this is a very likely situation in a DevOps process. There was also the attack vector, where a user with enough privileges in a Worker could lead the whole cluster to crash.
When listing the cluster nodes in the Master with the command kubectl get nodes, we only got one member and it was the original Master, although the other nodes were added to the cluster without errors.
After a reboot to the Master node, the cluster remained stable. When testing with two Workers with the same hostname and a different Master hostname, there was also instability in the cluster, and only the first Worker to be added to the cluster was shown in the output of the kubectl get nodes command.
Digging deeper, we were able to understand what was causing this instability. There is a race condition in the update of an etcd key. Etcd is used by the Kubernetes Master to store all cluster configuration and state data. The hostname of the cluster nodes is used to name a key in etcd, in the following format: /registry/minions/HOSTNAME – where HOSTNAME is the actual hostname of the node.
When two nodes share the same hostname, every time they communicate their state to the Master node, etcd updates the referred key. When checking the value of this key periodically, we proved the race condition, since the values of both nodes were shown randomly over time as shown in Figure 1.

Figure 1: Differences between two consecutive key updates
Besides the number of updates increase, on each update, several other keys (events) are also created and should be dispatched by Kubernetes components. This is what caused the cluster instability due to high CPU load on the Master node.
A video demonstrating the vulnerability can be found here. In addition to adding a Worker node with a hostname that already exists, it is also possible to exploit the vulnerability using the option –-hostname-override when adding a node to the cluster.
We validated this behavior against a public Kubernetes service provider, Azure Kubernetes Service (AKS), and we noticed that it adds a prefix to the hostname of the nodes. This behavior is enough to mitigate the described vulnerability.
Following our research, an issue was created in the official Kubernetes GitHub page, recommending two solutions to fix the vulnerability:
- prevent nodes with a duplicate hostname or –hostname-override value to join the cluster
- add a prefix/suffix to the etcd key name
Later, the Pull Request 81056 was created to address the vulnerability, following our first recommendation described above. The issue was fixed by rejecting a node joining the cluster if a node with the same name already exists #1711.
Discovering vulnerabilities like the one mentioned in this blog is why the Checkmarx Security Research team performs investigations. This type of research activity is part of our ongoing efforts to improve security for organizations worldwide.